ICU: Unicodeでの文字列照合・ソート [C++]
(2018.10) 新規作成.
二つのUnicode文字列が「同一」かどうかは、正規化した上で単に code point を比較していけばいい。このページでは, Unicode文字列の大小を判定する方法について解説する.
ICU 60.2 on Fedora 28 Linux でテストした。
この記事は, こちらの「Javaがポンコツ」という記事に触発された。「Java 6 でIVSを比較すると何が起こるか」の記事の誤り(続編) - Cafe Babe Javaがいかにポンコツか力説。
文字列の並べ替え
文字の並べ替えではない。
文字列をソートする (並べ替える) のは, code point 列を単純に比較する方法では上手くいかない. 用途によってはそれで足りる場合もあるが。
次の順序で並んでほしい;
- abc
- ABC
- abd
あるいは;
- あーく
- ああく
- あーち
まず大文字・小文字、音引きと平仮名を区別せず大らかに並べ替え、次にその中で並べ直す。長音は直前の文字を参照する必要もある。
IVS
IVS (Ideographic Variation Sequence) は, ある Unicode code point に対してグリフを特定するコード列.
このページが詳しい;
対応アプリとフォントの組み合わせで、グリフを出し分けることができる。この例は, U+4E0E に続けて U+E0101 を付けている。
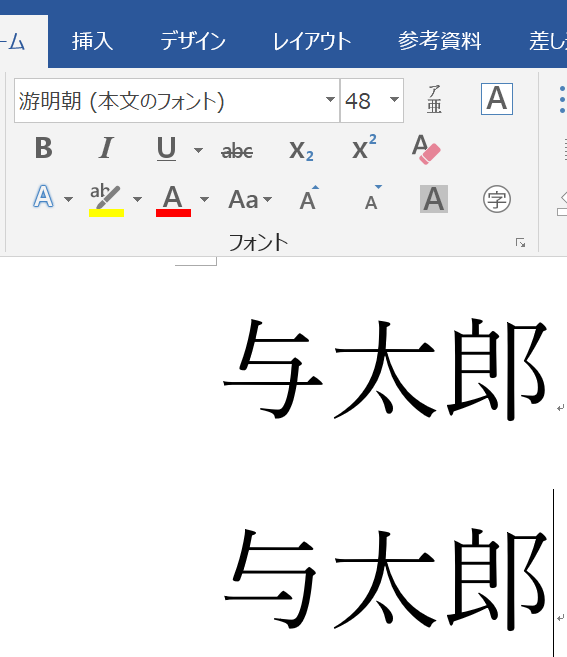
どの基底文字に対して異体字セレクタがあるかは、例えばこちら; AdobeJapan1 IVS異体字一覧
正規化でも異体字セレクタは失われない (当たり前。区別したいのだから.) が、文字列の照合、順序付けでは注意が必要。
ICU: Collatorクラス
ICU では, 照合順序の強度 (strength) を指定する。ルールベースの称号は Collatorクラスを使う。
文字列の照合は、ロケール依存になる。次のサンプルは, いくつかの文字列の組み合わせについて, 照合の強度を変えることで同一・異なるの判定がどのように変わるか、を示す。
IVS (Ideographic Variation Sequence) についても試した。Collator::IDENTICAL 以外では常に一致という判定になる。IVSは、Unicode の建前ではグリフを選ぶもので文字を選ぶものではないから、こうなる。
- #include <stdio.h>
- #include <unicode/coll.h> // Collator
- #include <unicode/uclean.h> // u_cleanup()
- using namespace std;
- void compare_and_print( Collator* collator,
- const UnicodeString& s, const UnicodeString& t,
- icu::Collator::ECollationStrength strength )
- {
- UErrorCode errc = U_ZERO_ERROR;
- collator->setStrength( strength );
- // LESS = -1, EQUAL = 0, GREATER = +1
- UCollationResult r = collator->compare(s, t, errc);
- printf("%d ", r);
- }
- void compare_all_levels( Collator* collator,
- const UnicodeString& s, const UnicodeString& t )
- {
- compare_and_print(collator, s, t, icu::Collator::PRIMARY);
- compare_and_print(collator, s, t, icu::Collator::SECONDARY);
- compare_and_print(collator, s, t, icu::Collator::TERTIARY);
- compare_and_print(collator, s, t, icu::Collator::QUATERNARY);
- compare_and_print(collator, s, t, icu::Collator::IDENTICAL);
- printf("\n");
- }
- #define _(x) UnicodeString(x)
- int main()
- {
- UErrorCode errc = U_ZERO_ERROR;
- auto loc = Locale("ja", "JP");
- icu::Collator* collator = icu::Collator::createInstance(loc, errc);
- compare_all_levels(collator, _("ABC"), _("abc") ); // 大文字
- compare_all_levels(collator, _("a"), _("\u24d0") ); // 囲み文字
- compare_all_levels(collator, _("あーち"), _("ああち") ); // 長音
- compare_all_levels(collator, _("せんこく"), _("せんごく") ); // 濁音
- compare_all_levels(collator, _("きよう"), _("きょう") ); // 拗音
- compare_all_levels(collator, _("与太郎"), _("与\U000E0101太郎") ); // IVS
- delete collator;
- u_cleanup(); // 必須
- return 0;
- }
実行結果;
0 0 1 1 1 0 0 -1 -1 -1 0 0 -1 -1 -1 0 -1 -1 -1 -1 0 0 1 1 1 0 0 0 0 -1
濁音が SECONDARY で区別され始める。ほかは TERTIARY から。上述のように, IVS は IDENTICAL のみで区別される。
L1~L4 などアルゴリズムはここで定義されている; UTS #10: Unicode Collation Algorithm. デフォルト設定は DUCET (Default Unicode Collation Element Table) と呼ばれ, Unicode 10.0 のものはこちら; allkeys-10.0.0.txt
ソートキー
いちいち PRIMARY で同一だったら SECONDARY で比較して, ... というコードを書くのは大変だし, convenience method として greaterOrEqual() などが用意されているが、そもそも重そう。
そこで, ソートキーを出力して保存しておき, これで並べ替える手がある。ソートキーから元の文字列を復元することはできないので、元の文字列も保存する必要がある。
次のサンプルは, ソートキーを表示する。
- #include <stdio.h>
- #include <array>
- #include <memory>
- #include <unicode/sortkey.h> // CollationKey
- #include <unicode/uclean.h> // u_cleanup()
- using namespace std;
- void dump(const unsigned char* ary, int len)
- {
- for (int i = 0; i < len; i++)
- printf("%02x ", ary[i]);
- printf("\n");
- }
- #define _(x) UnicodeString(x)
- void sort_key_test()
- {
- UErrorCode errc = U_ZERO_ERROR;
- auto loc = Locale("ja", "JP");
- unique_ptr<icu::Collator> collator(
- icu::Collator::createInstance(loc, errc));
- array<icu::CollationKey, 4> key;
- collator->getCollationKey(_("あーく"), key[0], errc);
- collator->getCollationKey(_("ああく"), key[1], errc);
- collator->getCollationKey(_("あーち"), key[2], errc);
- collator->getCollationKey(_("ああち"), key[3], errc);
- for (int i = 0; i < 4; i++) {
- int len;
- const unsigned char* p = key[i].getByteArray(len);
- dump(p, len);
- }
- }
- int main()
- {
- sort_key_test();
- u_cleanup(); // 必須
- return 0;
- }
実行結果:
5d 06 06 16 01 07 01 05 02 05 00 5d 06 06 16 01 07 01 07 00 5d 06 06 28 01 07 01 05 02 05 00 5d 06 06 28 01 07 01 07 00
このサンプルのなかで書いたとおりの順番になる。
ソートキーがICUのバージョンに対して安定かどうかは試していない。ICUのバージョンアップで異なる値になることは、十分にありそう。
そのほか
IVSは措いておくとして。
漢字について、包摂がだんだん厳しくなって、どんどん code point が割り当てられるようになっている。テキストの検索では、Unicode code point でも細かすぎ、もっと同一視して検索したいことも多い。
リンクだけ張っておく;
- 異体字同一視検索 | karak 「中日辞書 北辞郎」における異体字同一視。PHP によるコード例。
https://gist.github.com/scivola/bc61a59c47b72d446c1cリンク切れ- 異体字データベース 各種文献に記載されている異体字・関連字情報を収集・整理したもの. 素晴らしい。