ICU: Unicode正規化 (icu::Normalizer2) [C++]
(2005.4.30 この節を追加。)
(2018.9) ページ分割、最新化.
Unicode における正規化とは
Unicodeは、既存の多くの文字集合の文字を収録しているため、複数の異なったコード列が同じ文字を表す場合がある。これらをそのまま扱うのは検索などで困難が多いので、正規化 (Normalization) して, 特定のコード列に揃える。
Unicodeでの正規化には、NFD, NFKD, NFC, NFKCの4種類がある。
正規化は, まず, 文字を一定のルールで分解する. 2種類のルールがあり, 正規分解 Canonical Decomposition は文字を変えることなく分解する。互換分解 Compatibility Decomposition は意味が同じならより基本的な文字に変更して分解する。
ここで止めると, 正規化形式 NFD (正規分解) か NFKD (互換分解) になる。
NFC/NFKC は, NFD/NFKD で正規化したうえで, 正規結合 Canonical Composition で結合する。
Unicode 正規化のルールは、こちらで定義されている;
実用では、通常は NFC で正規化する。例えば、ユーザから入力やペーストされた文字列を, 正規化したうえでデータベースに保存するなど。検索キーになるフィールドは, NFKC もよく使う。
(2018.9) さらに, 大文字・小文字を区別しない場合は, NFKC_Casefold もある。
例えば、U+0041 U+030Aというコード列をNFCまたはNFKCで正規化すると次のようになる。NFD/NFKDは逆向きの変換を行う。
| A | COMBINING RING ABOVE | C/KC → | Å |
| 0041 | 030A | 00c5 |
ひらがなでも同様。濁音を結合するか。
| か | COMBINING KATAKANA-HIRAGANA VOICED SOUND MARK | C/KC → | が |
| 304b | 3099 | 304c |
NFKC / NFKD は、互換分解 Compatibility Decomposition を行う。互換分解は、互換文字をより基本的な文字に置換するほかに、丸付き文字などを展開する。
| ① | KC/KD → | 1 |
| 2460 | 0031 |
| ㊤ | KC/KD → | 上 |
| 32a4 | 4e0a |
| ㌶ | KC/KD → | ヘ | ク | タ | ー | ル |
| 3336 | 30d8 | 30af | 30bf | 30fc | 30eb |
互換漢字と variant
(2018.9 追加)
互換漢字は, 正規化形式が何であれ (NFKC/NFKDだけでなく), 統合漢字に変換される。しかし、正規化しつつグリフを区別したいという需要がある。人名など。
| 侮 | 侮 |
| fa30 | 4fae |
Unicode 10.0 の NormalizationTest.txt ファイルはこうなっている。どの正規化形式であれ、変換されることが分かる。
FA30;4FAE;4FAE;4FAE;4FAE; # (侮; 侮; 侮; 侮; 侮; ) CJK COMPATIBILITY IDEOGRAPH-FA30
Unicode 6.3 で, 互換漢字に対して Variation Selector (VS) が振られた。StandardizedVariants.txt には次の行がある. これにより 4FAE FE00 という列で, U+FA30 と同じグリフが表示されることが期待できる。
4FAE FE00; CJK COMPATIBILITY IDEOGRAPH-FA30; 4FAE FE01; CJK COMPATIBILITY IDEOGRAPH-2F805;
対応しているアプリケーションとフォントを組み合わせれば、確かにグリフの出し分けができる. この二文字は、両方とも U+4FAE で, 片方に VS を付けている;
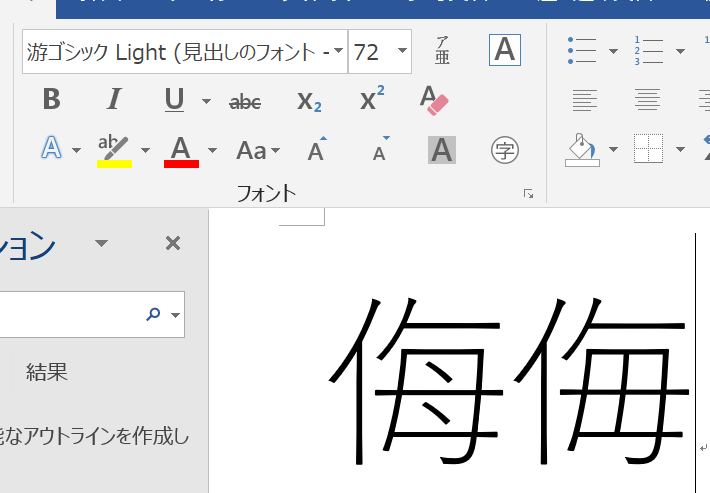
しかしながら, U+FA30 を正規化したときに 4FAE FE00 になるわけではないようだ。NormalizationTest.txt ファイルを眺めると, 正規化で複数の Code Point に展開 (分解) しても構わないが, 互換漢字はそのように定められていない.
ICU: 正規化サンプル
ICU で正規化するプログラムを書いてみる。Fedora 28 Linux には, ICU 60.2 のパッケージがある。このバージョンは Unicode 10.0 に対応する.
文字列全体を単に正規化するのは, 難しくない。normalize() などのメソッドを呼び出すだけ。以下では, ファイルを読み込みながら正規化したりできるように、少しずつ正規化するケースを作る。
しかし作ってから思ったが, 正規化するようなケースは極端に長いデータは考えにくく, 逆に短いなら文字列オブジェクトを作っても問題なく, あまり意味がなかった。
icu::Normalizer2クラス
新しいプログラムでは, icu::Normalizer2 を使おう。ICU 4.4 で安定し、ICU 49 で拡充された。
- #include <stdio.h>
- #include <assert.h>
- #include <unicode/normalizer2.h>
- #include <unicode/uclean.h> // u_cleanup()
- void dump(const UnicodeString& str)
- {
- printf("len=%d ", str.length());
- for ( int i = 0; i < str.length(); i = str.moveIndex32(i, +1) ) {
- UChar32 uc = str.char32At(i);
- printf("%x ", uc);
- }
- printf("\n");
- }
- static void norm_seg( const UnicodeString& seg, const icu::Normalizer2* normzr )
- {
- assert(normzr);
- UErrorCode errc = U_ZERO_ERROR; // 初期化重要
- UNormalizationCheckResult check = normzr->quickCheck(seg, errc);
- printf(" len=%d quick=%d quickYes=%d ",
- seg.length(), // サロゲートペアだと, 1 code point でも len = 2
- check,
- normzr->spanQuickCheckYes(seg, errc) );
- // 文字列に追加するなら normalizeSecondAndAppend() と組み合わせる.
- if (check == UNORM_YES)
- dump(seg);
- else {
- UnicodeString dest;
- normzr->normalize(seg, dest, errc);
- dump(dest);
- }
- //delete normzr; これは invalid pointer になる.
- }
- int main()
- {
- UErrorCode errc = U_ZERO_ERROR; // 初期化重要
- u_init(&errc);
- UnicodeString str = "あX㌶a\u0308\u0323か\u3099e\u0304\u0301\u0323\ufa30𠮟𩸽";
- errc = U_ZERO_ERROR;
- const icu::Normalizer2* normzr = icu::Normalizer2::getNFKCInstance(errc);
- assert(normzr);
- // spanQuickCheckYes() は 先頭から quickCheck() == YES となる範囲の長さを
- // 返す.
- printf("quickCheck = %d\n", normzr->spanQuickCheckYes(str, errc) ); //=>2
- int start = 0;
- int i;
- // i++ ではサロゲートペアで不味い.
- for ( i = 0; i < str.length(); i = str.moveIndex32(i, +1) ) {
- // より効率的にいくなら, spanQuickCheckYes() の長さ分だけ進めて, 進めら
- // れない場合に, 以下のコードで正規化する.
- UChar32 uc = str.char32At(i);
- // hasBoundaryBefore() は基底文字のとき true
- // 結合文字がどれだけ続くかは、読んでみないと分からない.
- if ( normzr->hasBoundaryBefore(uc) && i - start > 0 ) {
- // 基底文字の直前までを処理する.
- const UnicodeString& seg = str.tempSubString(start, i - start);
- norm_seg(seg, normzr);
- start = i;
- }
- printf("%d: %x\n", i, uc);
- }
- // 最後のセグメントを忘れずに.
- if ( i - start > 0 ) {
- const UnicodeString& seg = str.tempSubString(start, i - start);
- norm_seg(seg, normzr);
- }
- // delete normzr; これも invalid pointer になる.
- u_cleanup(); // 必須
- return 0;
- }
Unicode文字列は基底文字の後ろにいくらでも結合文字が続きうる。したがって, 基底文字が出てきたらその直前までを正規化する, の繰り返しで、少しずつ正規化できる。上のサンプルでは norm_seg() が1文字だけ正規化する.
hasBoundaryBefore() は引数の code point が基底文字のときに真を返す。ここが区切りになる。
quickCheck() が UNORM_YES を返すような文字列は、正規化済みなので、そのまま利用できる。
実行結果:
quickCheck = 2
0: 3042
len=1 quick=1 quickYes=1 len=1 3042
1: 58
len=1 quick=1 quickYes=1 len=1 58
2: 3336
len=1 quick=0 quickYes=0 len=5 30d8 30af 30bf 30fc 30eb
3: 61
4: 308
5: 323
len=3 quick=0 quickYes=0 len=2 1ea1 308
6: 304b
7: 3099
len=2 quick=2 quickYes=0 len=1 304c
8: 65
9: 304
10: 301
11: 323
len=4 quick=0 quickYes=0 len=3 1eb9 304 301
12: fa30
len=1 quick=0 quickYes=0 len=1 4fae
13: 20b9f
len=2 quick=1 quickYes=2 len=2 20b9f
15: 29e3d
len=2 quick=1 quickYes=2 len=2 29e3d
icu::Normalizerクラス
icu::Normalizer クラスは古い。ICU 56 で非推奨 (deprecated) になった。
下のサンプルでは icu::Normalizer#first() と next() で少しずつ正規化しているように見えるが, UCharCharacterIterator クラスが確定した長さの文字列を取るため, 実際にはそうではない。
本当に不定長の文字列データを少しずつ正規化するには, CharacterIterator 抽象クラスをがっつり実装しなければならず, かなり大変そう。
- #include <stdio.h>
- #include <assert.h>
- #include <unicode/normlzr.h>
- #include <unicode/schriter.h> // StringCharacterIterator
- // 直接 CharacterIterator から派生させるのは大変
- class MyChIter: public UCharCharacterIterator
- {
- typedef UCharCharacterIterator super;
- public:
- MyChIter(const UnicodeString& str): super(str.getBuffer(), str.length()),
- m_str(str), m_pos(0), m_end(str.length()) { }
- virtual ~MyChIter() { }
- // 必要に応じて override する.
- private:
- const UnicodeString m_str;
- int m_pos;
- const int m_end;
- };
- int main()
- {
- // ◆合字
- // ヘクタール NFC ではママ
- // ◆結合文字列 combining sequence <=> 合成済み文字 precomposed character
- // a, U+0308 (DIAERESIS), U+0323 (DOT BELOW)
- // => 1EA1 'LATIN SMALL LETTER A WITH DOT BELOW' 0308
- // か, U+3099 (濁点) => 304C
- // e, U+0304 (MACRON), U+0301 (ACUTE), U+0323 (DOT BELOW)
- // => 1EB9 'LATIN SMALL LETTER E WITH DOT BELOW' 0304 0301
- // 0304 0301 をスキップして結合してることに注目!
- // ◆互換漢字
- // 侮 U+FA30 => どの正規化形式でも変換される.
- UnicodeString str = "㌶a\u0308\u0323か\u3099e\u0304\u0301\u0323\ufa30𠮟𩸽";
- // もちろん単に文字列を渡すコンストラクタもあるが, イテレータを試す.
- // CharacterIterator インスタンスを渡す.
- icu::Normalizer norm(MyChIter(str), UNORM_NFC);
- // サロゲートペアになる範囲も, 二つにならず, 32bit 単位で得られる.
- for (UChar32 uc = norm.first(); uc != norm.DONE; uc = norm.next() )
- printf("%x ", uc);
- printf("\n");
- return 0;
- }
実行結果:
3336 1ea1 308 304c 1eb9 304 301 4fae 20b9f 29e3d
Normalizer のコンストラクタに正規化方法を渡す。
UNORM_NFD | 正規分解 |
UNORM_NFKD | 互換分解 |
UNORM_NFC | 正規分解したうえで正規結合 |
UNORM_NFKC | 互換分解したうえで正規結合 |
リンク
Unicode正規化 もっとも詳しい解説。