異なる文字コードのテキストを混在させるには
2005.4.2 新規公開。1999.3.15の日記を加筆。
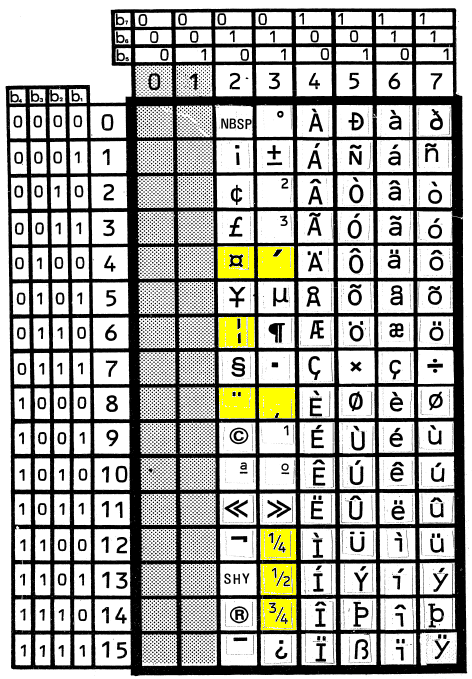
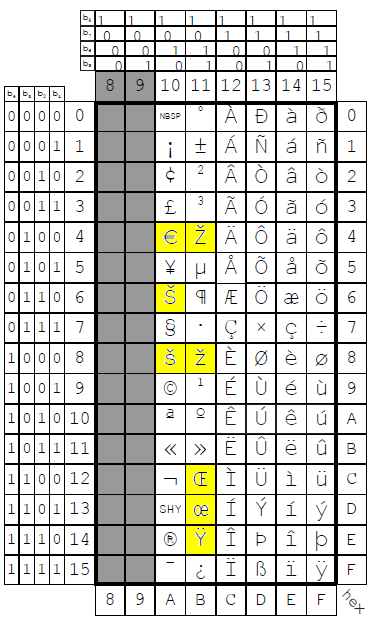
ISO 8859文字コード
もはや話は古くなるが、ユーロを表す文字を導入するために、ISO 8859-1に含まれる文字をいくつか入れ替えて、ISO 8859-15が作られた。FIELD OF UTILIZATION には、the EURO SIGN and provides support for the French, and Finnish languages in addition. とある。Finnish はフィンランド語ですか。サポートされる言語は、デンマーク語、ドイツ語、英語、スペイン語、フィンランド語、フランス語、アイスランド語、イタリア語、オランダ語、ノルウェー語、ポルトガル語、スウェーデン語。
追加された文字は、ユーロ記号と、CARON付きアルファベットが何文字か。CARON付きアルファベットは、8859-2, 8859-4にも入っている。
| コード | 名前 | Unicode |
|---|---|---|
| A4 | EURO SIGN | U+20AC |
| A6 | LATIN CAPITAL LETTER S WITH CARON | U+0160 |
| A8 | LATIN SMALL LETTER S WITH CARON | U+0161 |
| B4 | LATIN CAPITAL LETTER Z WITH CARON | U+017D |
| B8 | LATIN SMALL LETTER Z WITH CARON | U+017E |
| BC | LATIN CAPITAL LIGATURE OE | U+0152 |
| BD | LATIN SMALL LIGATURE OE | U+0153 |
| BE | LATIN CAPITAL LETTER Y WITH DIAERESIS | U+0178 |
ところで、ISO/IEC 8859 Information technology -- 8-bit single-byte coded graphic character sets -- は、複数の分冊からなっていて(マルチパート)、その一覧は次のとおり。
- 8859-1:1998 Part 1: Latin alphabet No. 1
- 8859-2:1999 Part 2: Latin alphabet No. 2
- 8859-3:1999 Part 3: Latin alphabet No. 3
- 8859-4:1998 Part 4: Latin alphabet No. 4
- 8859-5:1999 Part 5: Latin/Cyrillic alphabet
- 8859-6:1999 Part 6: Latin/Arabic alphabet
- 8859-7:2003 Part 7: Latin/Greek alphabet
- 8859-8:1999 Part 8: Latin/Hebrew alphabet
- 8859-9:1999 Part 9: Latin alphabet No. 5
- 8859-10:1998 Part 10: Latin alphabet No. 6
- 8859-11:2001 Part 11: Latin/Thai alphabet
- 8859-12: × 欠番
- 8859-13:1998 Part 13: Latin alphabet No. 7
- 8859-14:1998 Part 14: Latin alphabet No. 8
- 8859-15:1999 Part 15: Latin alphabet No. 9
- 8859-16:2001 Part 16: Latin alphabet No. 10
複数の文字コードに対応する
さて、これら複数の文字コードをサポートするようなプログラムを書く場合、どうするか。
これらの文字コードに含まれる文字(文字集合)は、どれも異なっている。また、複数の文字コードに含まれる文字も多い。
次の方針があるだろう。
- 入出力の段階で、複数の文字コードの文字集合をすべて含むスーパーセットに変換する
- テキストに文字コード情報を付与する
前者は、たとえばUnicodeに変換してしまって、プログラム内部ではUnicodeのみを扱うようにする。それぞれの文字コードの文字集合が小さく、かつ一致していない状況では、この方針がいいと思う。
日本で使われるシフトJIS / EUC-JP / ISO-2022-JPは、文字集合が基本的に同じなので、やはりプログラム内部でどれか(シフトJISまたはEUC-JP)に変換してしまう方法がよく使われる。
round-trip conversionは確保できるのか、正規化してもいいのか、などに注意が必要。
文字コード付きテキスト
サポートしたい文字コードの文字がうまくUnicodeに載らない場合は、テキストに文字コード情報を付けることになる。
この場合は、同じ文字が複数のコードポイントで表現されることがあるので、検索などで、うまく文字を同一視するようにする必要がある。